clusterdatabase-as-a-servicedata-infrastructuregolangkubernetesmanaged-servicesoperatorpostgrespostgres-operatorpostgresql
* Lookup function installation Due to reusing a previous database connection without closing it, lookup function installation process was skipping the first database in the list, installing twice into postgres db instead. To prevent that, make internal initDbConnWithName to overwrite a connection object, and return the same object only from initDbConn, which is sort of public interface. Another solution for this would be to modify initDbConnWithName to return a connection object and then generate one temporary connection for each db. It sound feasible but after one attempt it seems it requires a bit more changes around (init, close connections) and doesn't bring anything significantly better on the table. In case if some future changes will prove this wrong, do not hesitate to refactor. Change retry strategy to more insistive one, namely: * retry on the next sync even if we failed to process one database and install pooler appliance. * perform the whole installation unconditionally on update, since the list of target databases could be changed. And for the sake of making it even more robust, also log the case when operator decides to skip installation. Extend connection pooler e2e test with verification that all dbs have required schema installed. |
||
|---|---|---|
| .github/ISSUE_TEMPLATE | ||
| charts | ||
| cmd | ||
| docker | ||
| docs | ||
| e2e | ||
| hack | ||
| kubectl-pg | ||
| manifests | ||
| pkg | ||
| ui | ||
| .flake8 | ||
| .gitignore | ||
| .golangci.yml | ||
| .travis.yml | ||
| .zappr.yaml | ||
| CODEOWNERS | ||
| CONTRIBUTING.md | ||
| LICENSE | ||
| MAINTAINERS | ||
| Makefile | ||
| README.md | ||
| SECURITY.md | ||
| build-ci.sh | ||
| delivery.yaml | ||
| go.mod | ||
| go.sum | ||
| mkdocs.yml | ||
| run_operator_locally.sh | ||
README.md
Postgres Operator

![]()


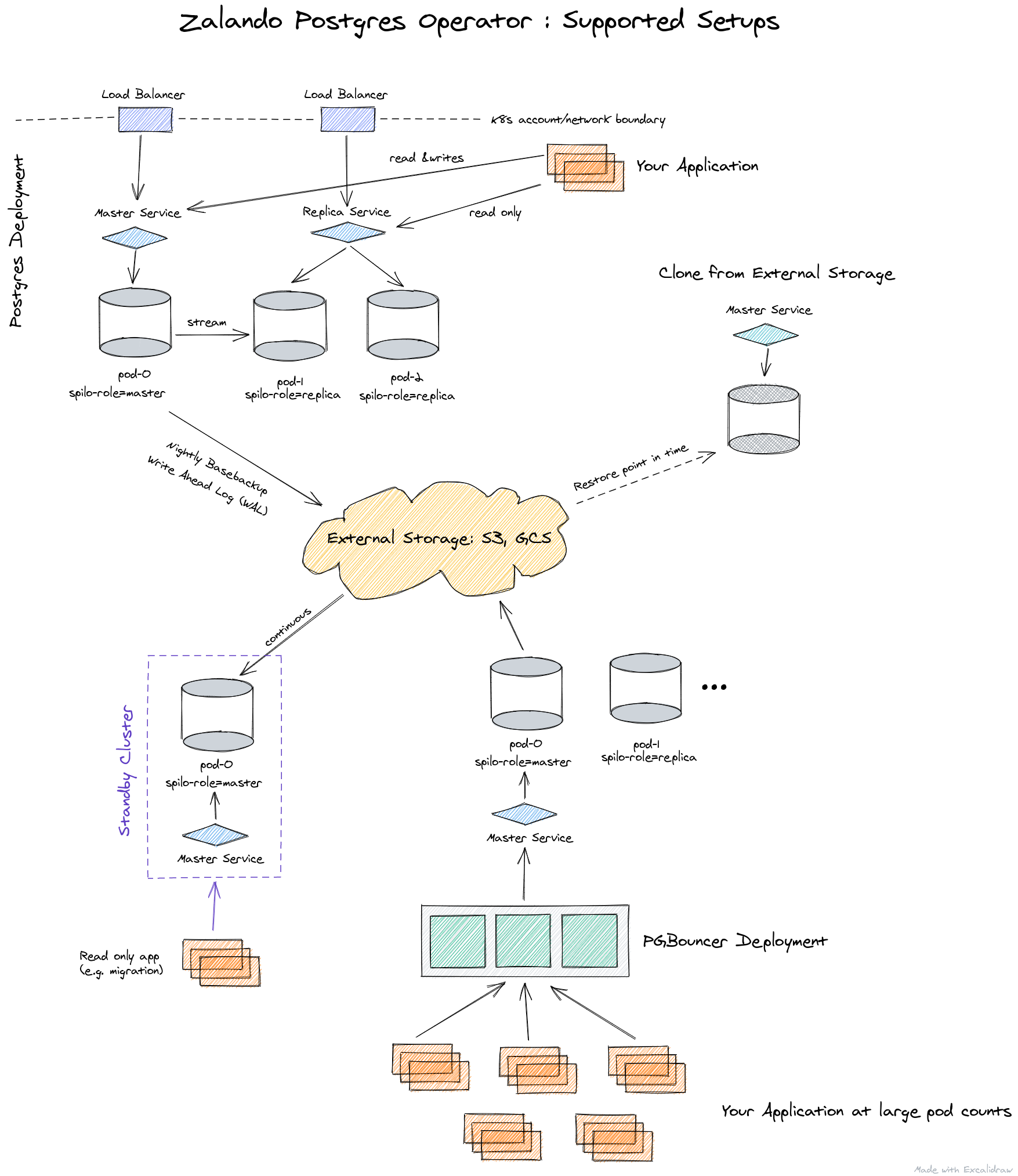
The Postgres Operator delivers an easy to run highly-available PostgreSQL clusters on Kubernetes (K8s) powered by Patroni. It is configured only through Postgres manifests (CRDs) to ease integration into automated CI/CD pipelines with no access to Kubernetes API directly, promoting infrastructure as code vs manual operations.
Operator features
- Rolling updates on Postgres cluster changes, incl. quick minor version updates
- Live volume resize without pod restarts (AWS EBS, others pending)
- Database connection pooler with PGBouncer
- Restore and cloning Postgres clusters (incl. major version upgrade)
- Additionally logical backups to S3 bucket can be configured
- Standby cluster from S3 WAL archive
- Configurable for non-cloud environments
- Basic credential and user management on K8s, eases application deployments
- UI to create and edit Postgres cluster manifests
- Works well on Amazon AWS, Google Cloud, OpenShift and locally on Kind
PostgreSQL features
- Supports PostgreSQL 12, starting from 9.6+
- Streaming replication cluster via Patroni
- Point-In-Time-Recovery with pg_basebackup / WAL-E via Spilo
- Preload libraries: bg_mon, pg_stat_statements, pgextwlist, pg_auth_mon
- Incl. popular Postgres extensions such as decoderbufs, hypopg, pg_cron, pg_partman, pg_stat_kcache, pgq, plpgsql_check, postgis, set_user and timescaledb
The Postgres Operator has been developed at Zalando and is being used in production for over two years.
Getting started
For a quick first impression follow the instructions of this tutorial.
Supported setups of Postgres and Applications
Documentation
There is a browser-friendly version of this documentation at postgres-operator.readthedocs.io
- How it works
- Installation
- The Postgres experience on K8s
- The Postgres Operator UI
- DBA options - from RBAC to backup
- Build, debug and extend the operator
- Configuration options
- Postgres manifest reference
- Command-line options and environment variables
Community
There are two places to get in touch with the community:
- The GitHub issue tracker
- The #postgres-operator slack channel